|
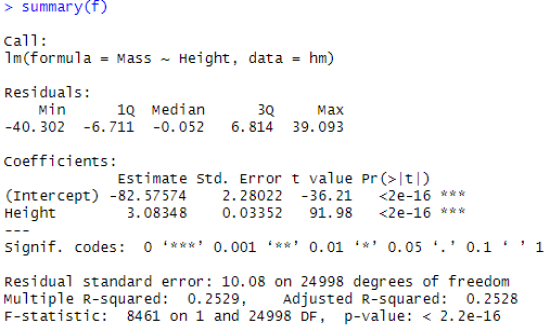
Linear Model CoefficientsSummary of the linear model in R gives the following coefficient details:
|
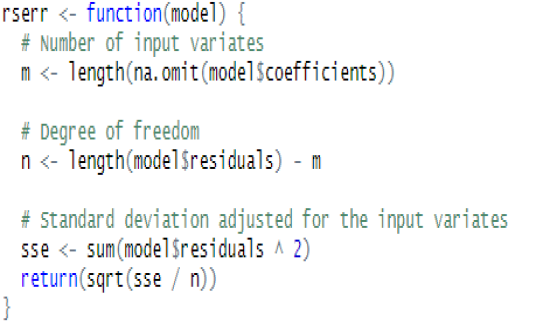
Residual Standard ErrorThe residuals are the difference between the actual values of the response you’re predicting and predicted values from your regression. The Residual Standard Error is simply the standard deviation of your residuals. The Degrees of Freedom is the difference between the number of observations included in your training sample and the number of variables used in your model, including the intercept. For our data set, rserr function returns 10.07952, which matches the summary above. |
|

|
Multiple R SquaredMultiple R2 (or simply R2) is the metric for evaluating the goodness of fitness of your model. Higher is better with 1 being the best. The value corresponds to the amount of variability in the prediction that is explained by the model. WARNING: While a high R-squared indicates good correlation, correlation does not always imply causation. For our data set, mrsqr function returns 0.2528667, which matches the summary above. |
Adjusted R SquaredAdjusted R2 (or Radj2) can be interpreted as a less biased estimator of the goodness of fitness of your model, when compared to R2. This takes into account the sudden increase in the value of R2 when extra predictor variables are added to the model. The Radj2 can be negative and its value will always be less than or equal to that of R2. If we introduce predictor variables in the model one at a time, in the order of their importance, we will observe that Radj2 will reach a maximum, before it starts decreasing. The model for which Radj2 is maximum has the ideal combination of predictor variables, without any redundant terms. For our data set, arsqr function returns 0.2528368, which matches the summary above. |

|

|
F StatisticF-Statistic performs an F-test on the model. This takes the parameters of our model and compares them to a model that has fewer parameters. In theory the model with more parameters should fit better.
The DF, or degrees of freedom, pertains to the number of predictor variables in the model. For our data set, fstat function returns 8460.554, which matches the summary above. |
© Copyright 2019 cKlear Analytics